KV Cache Quantization and Test Results¶
For the LLaMa-7B fp16 model with a maximum length of 2048, the server requires approximately 1030MB of GPU memory to store kv_cache for each concurrent session created. This means that even an A100 80G can only serve a limited number of users.
To reduce runtime GPU memory usage, we have implemented PTQ quantization for kv cache, using the following formula:
zp = (min+max) / 2
scale = (max-min) / 255
quant: q = round( (f-zp) / scale)
dequant: f = q * scale + zp
How to Enable KV Cache INT8¶
Step One¶
Convert the Hugging Face model format to the TurboMind inference format to create a workspace directory.
lmdeploy convert internlm-chat-7b /path/to/internlm-chat-7b
If you already have a workspace directory, skip this step.
Step Two¶
Get the quantization parameters by these two steps:
# get minmax
lmdeploy lite calibrate \
$HF_MODEL \
--calib-dataset 'ptb' \ # Support c4, ptb, wikitext2, pileval
--calib-samples 128 \ # Number of samples in the calibration set, if the memory is not enough, it can be adjusted appropriately
--calib-seqlen 2048 \ # Length of a single text, if the memory is not enough, you can adjust it appropriately
--work-dir $WORK_DIR \ # Directory for saving quantized statistical parameters and quantized weights in Pytorch format
# get quant parameters
lmdeploy lite kv_qparams \
$WORK_DIR \ # Directory of the last output
workspace/triton_models/weights/ \ # Directory to save the quantization parameters
--num-tp 1 \ # Number of GPUs used for Tensor parallelization, keep it consistent with deploy.py
kv_qparams will generate fp32 scaling factors in the weights directory. The file format is a binary produced by numpy.tofile.
You can also first set turbomind_dir to a private directory, then copy the scaling factors into workspace/triton_models/weights/.
Step Three¶
Modify workspace/triton_models/weights/config.ini:
Set quant_policy to 4. This means enabling kv_cache int8
GPU Memory Test¶
The test object is the internlm-chat-7b model. Testing method:
Use
deploy.pyto convert the model, modify the maximum concurrency in theworkspaceconfiguration; adjust the number of requests inllama_config.ini.Compile and run
bin/llama_triton_exampleto obtain the GPU memory situation of the fp16 version under different batch_size.Enable quantization, re-run
bin/llama_triton_exampleto obtain the GPU memory situation of the int8 version under different batch_size.
Below shows the comparison of GPU memory between the two versions:
| batch_size | fp16 memory(MiB) | int8 memory(MiB) | diff(MiB) |
|---|---|---|---|
| 8 | 22337 | 18241 | -4096 |
| 16 | 30593 | 22369 | -8224 |
| 32 | 47073 | 30625 | -16448 |
| 48 | 63553 | 38881 | -24672 |
Compared to directly quantizing Weight (such as GPTQ-for-LLaMa), we have done a comparative estimation of memory growth in the 7B model for both methods, with some data from llama.cpp.
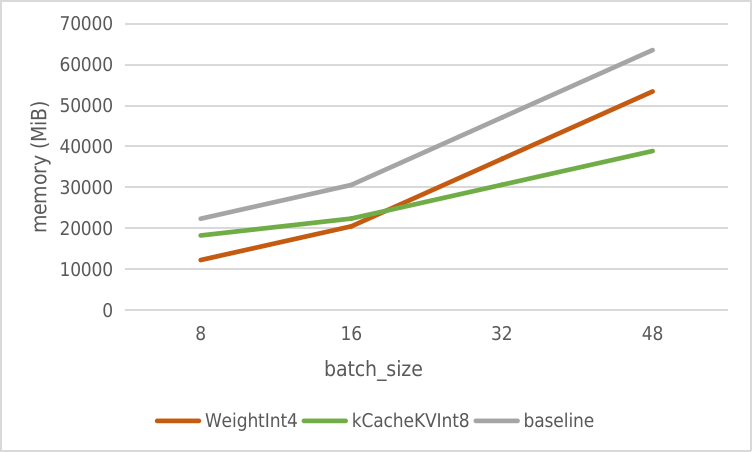
As can be seen, the fp16 version requires 1030MB of GPU memory for each concurrency, so quantizing kv_cache can significantly reduce the rate of increase of runtime memory.
Accuracy Test¶
The test object is the internlm-chat-7b command model.
Below is the result of PTQ quantization of kCacheKVInt8 method with only 128 randomly selected data from the c4 dataset. The accuracy was tested using opencompass before and after quantization.
| task | dataset | metric | int8 | fp16 | diff |
|---|---|---|---|---|---|
| Language | winogrande | accuracy | 60.77 | 61.48 | -0.71 |
| Knowledge | nq | score | 2.69 | 2.60 | +0.09 |
| Reasoning | gsm8k | accuracy | 33.28 | 34.72 | -1.44 |
| Reasoning | bbh | naive_average | 20.12 | 20.51 | -0.39 |
| Understanding | openbookqa_fact | accuracy | 82.40 | 82.20 | +0.20 |
| Understanding | eprstmt-dev | accuracy | 90.62 | 88.75 | +1.87 |
| Safety | crows_pairs | accuracy | 32.56 | 31.43 | +1.13 |
Note that both kCacheKVInt8 and WeightInt4 methods can be enabled at the same time.